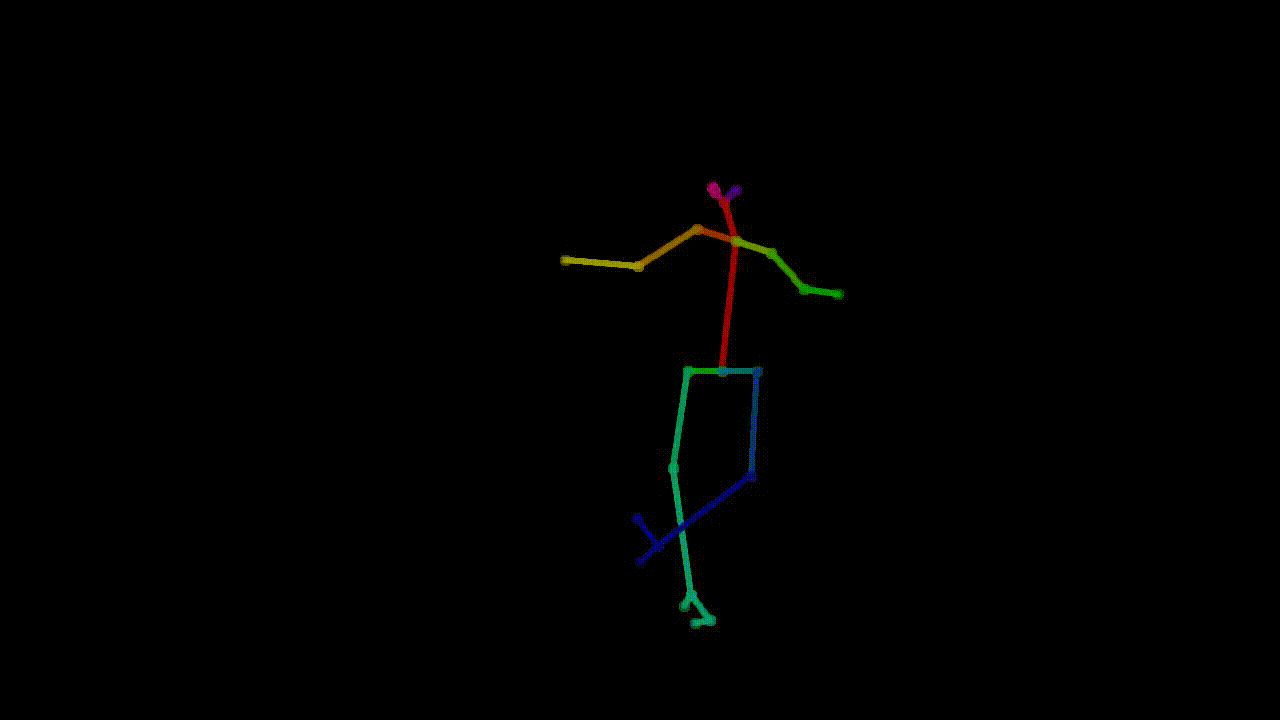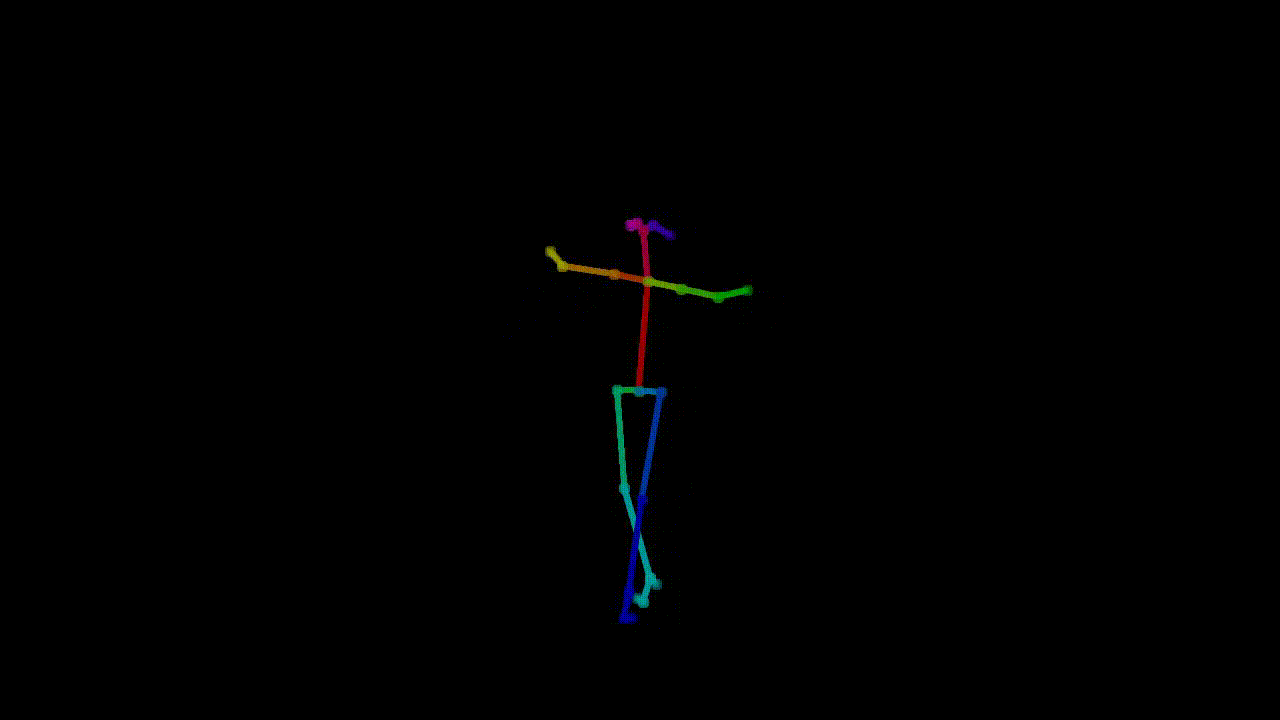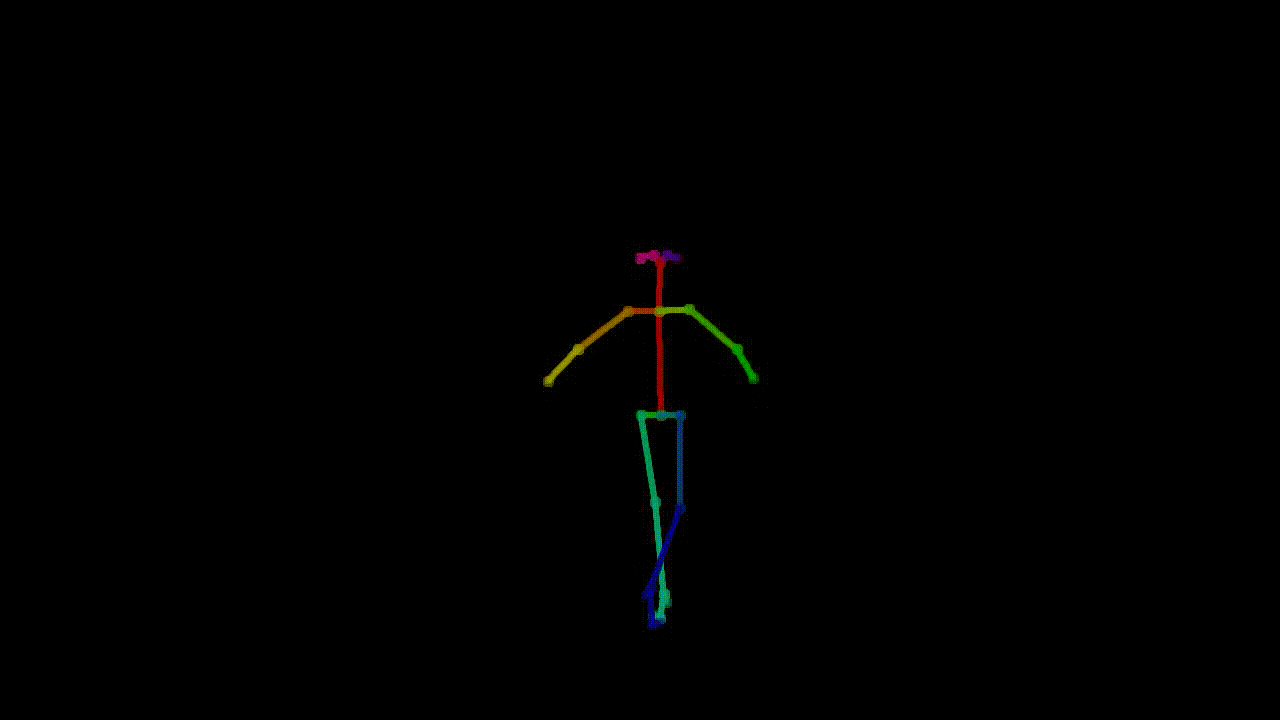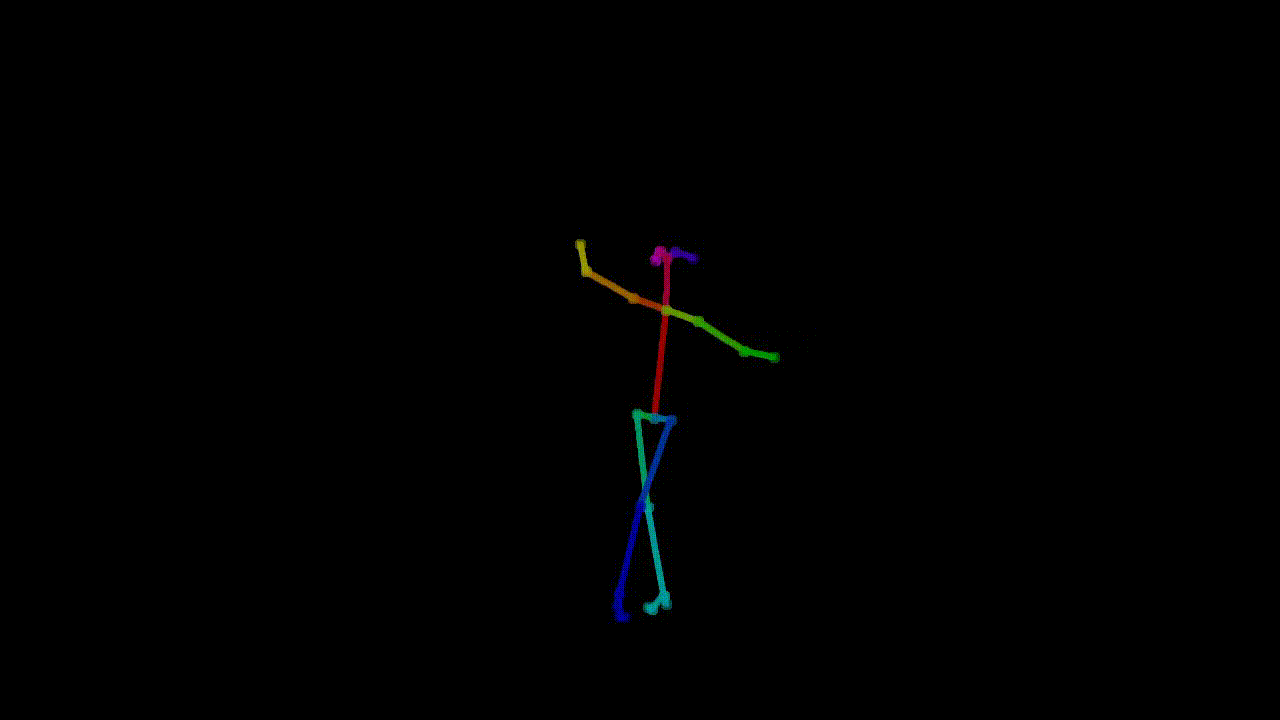
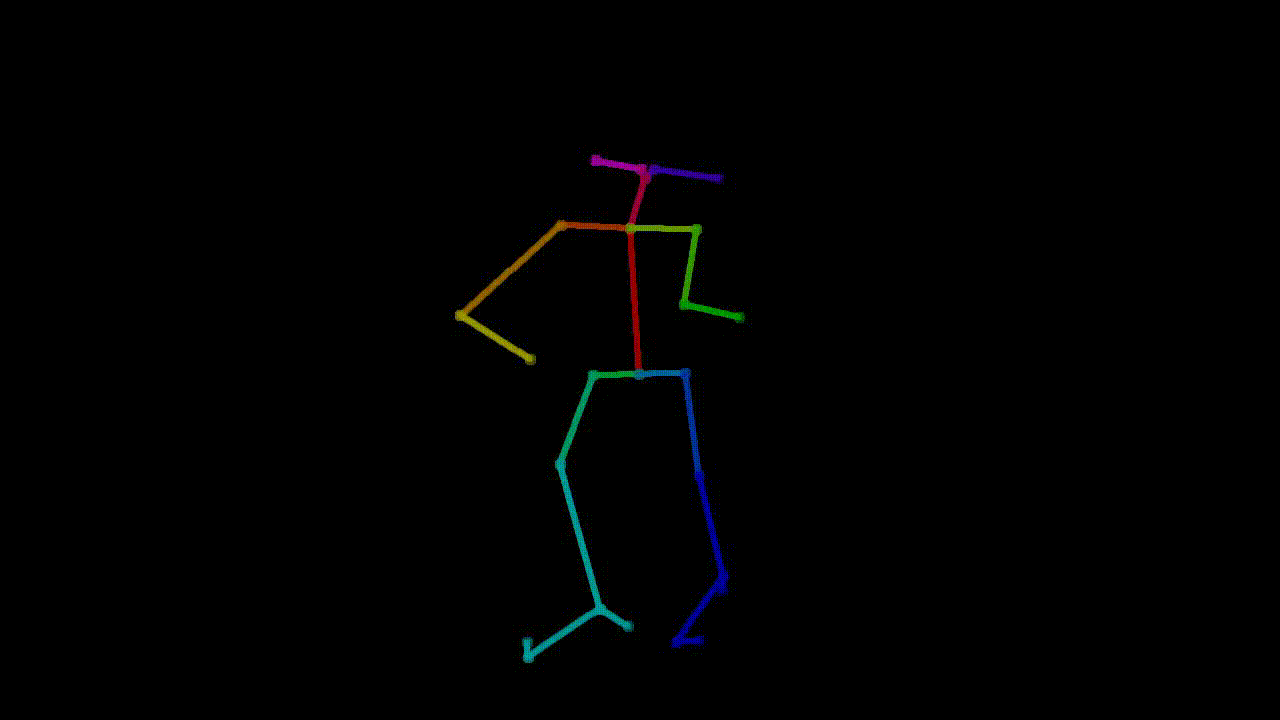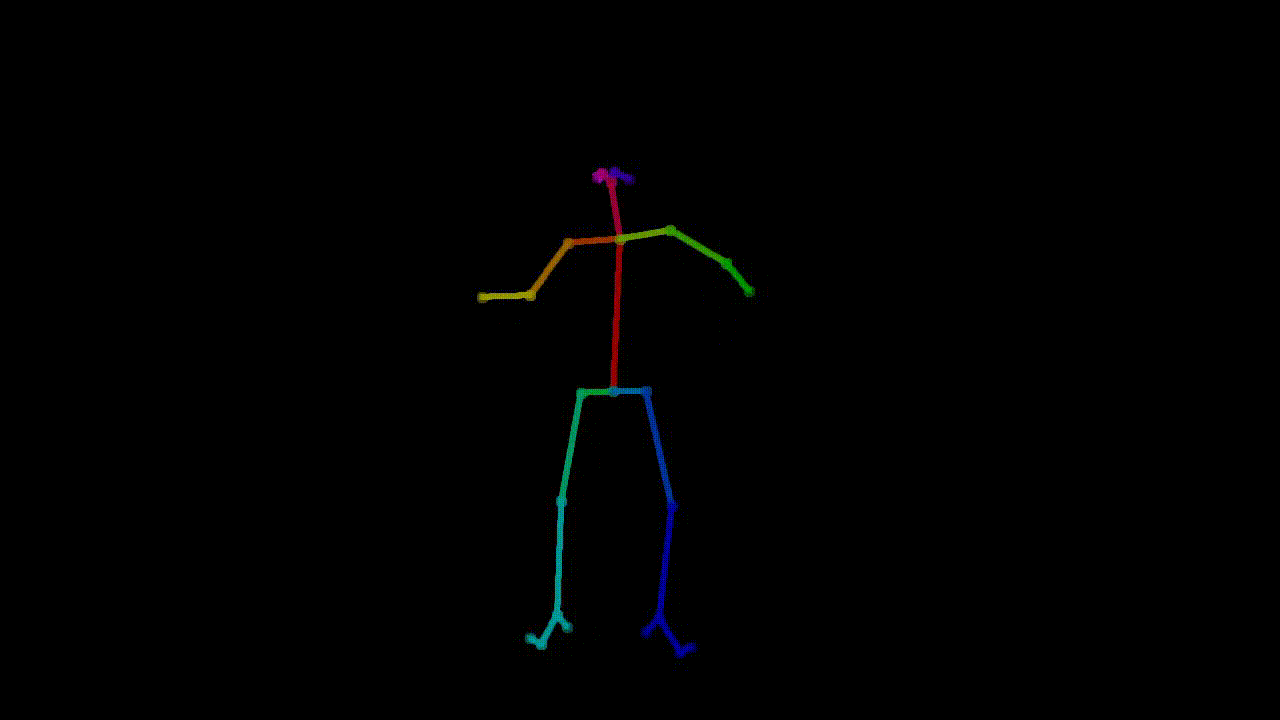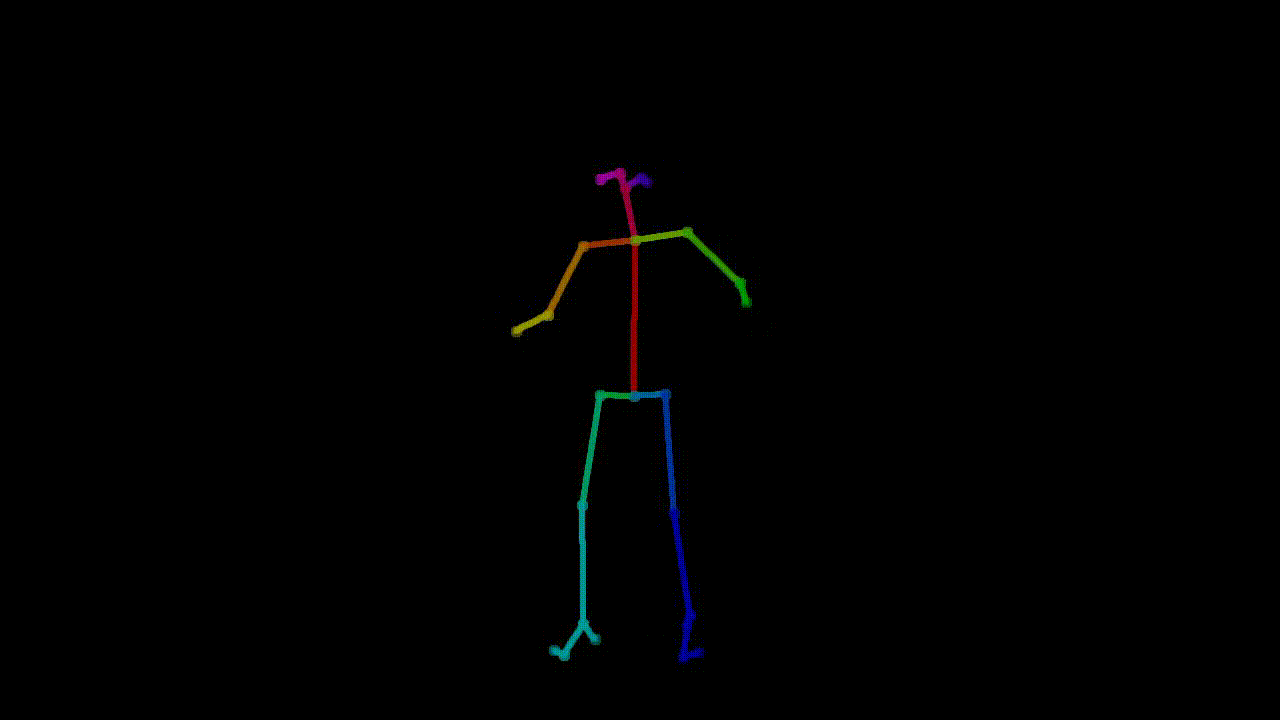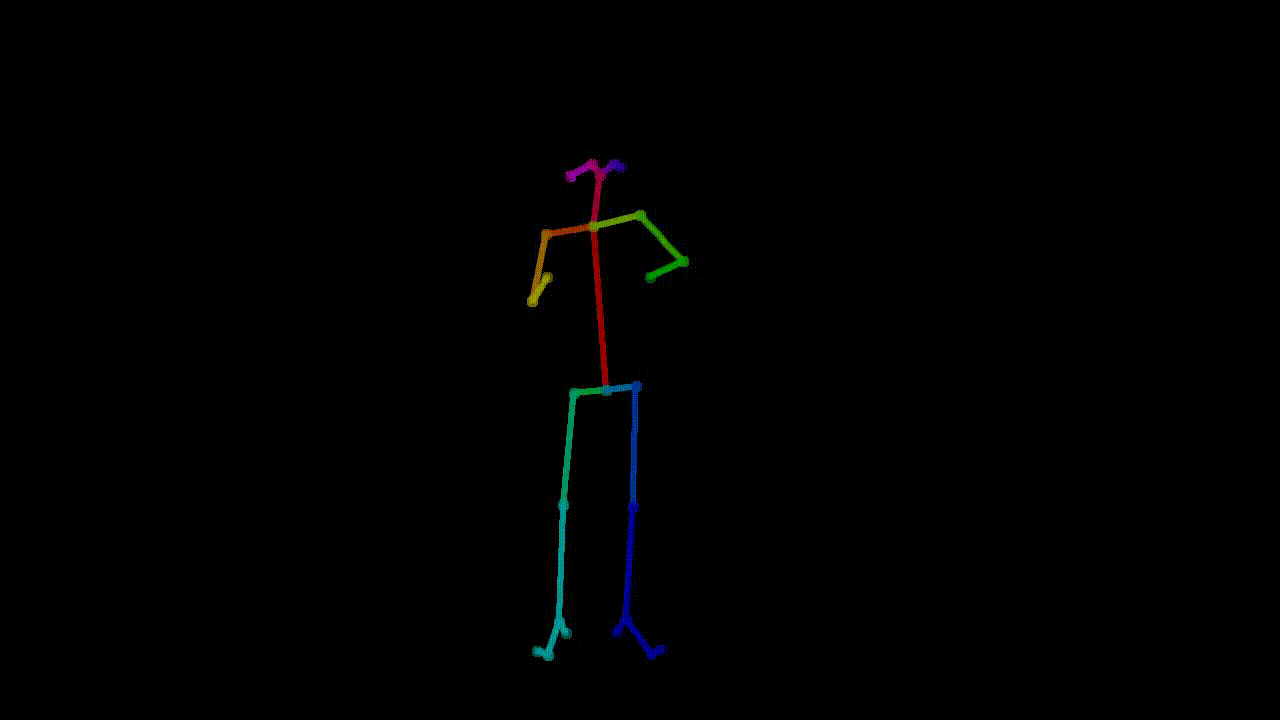As machine learning practitioners explore new ways to create art, introducing these innovations to the art community becomes essential. Our project aims to do just that: make it easy for choreographers and
dancers to use machine learning models that create dance from music.
New artificial intelligence (AI) research is finding its way into an unexpected part of society: dance
It comes as no surprise that computers are deeply involved in art. Photographers have been using computers to edit their work for ages, digital designers focus on creating art intended to be enjoyed on computers, and singers use computers to modify and enhance their voices. Up until now, however, choreographers have been using computers solely for gaining inspiration, sharing their work, and possibly for arranging music.
Machine learning (ML) breaks us out of this box. Where before choreographers and dancers could only look
at videos and physically try out how different moves would look, ML now enables us to do much much more.
It opens us to a new world of possibilities and allows us to ask questions we never dared ask before:
How would Michael Jackson dance to today’s music?
What would a J-pop dance look like if choreographed to the sounds of the NY subway?
What genre of dance lies between ballet and hip-hop? How does it look like?
How would a ballet dance look like if it was choreographed to a song by The Weeknd?
Can we make a dance based on cartoons?
Project Overview
Dataset Collection
Compile unique datasets embodying various dance styles, genres of music,
and actual dancers.
Backend Computing
Adapt and deploy a state-of-the-art dance generation model to create
long and expressive dance sequences.
User Experience
Streamline user interaction with the model so that non-experts can
easily train the model on their own datasets and test it on new music.
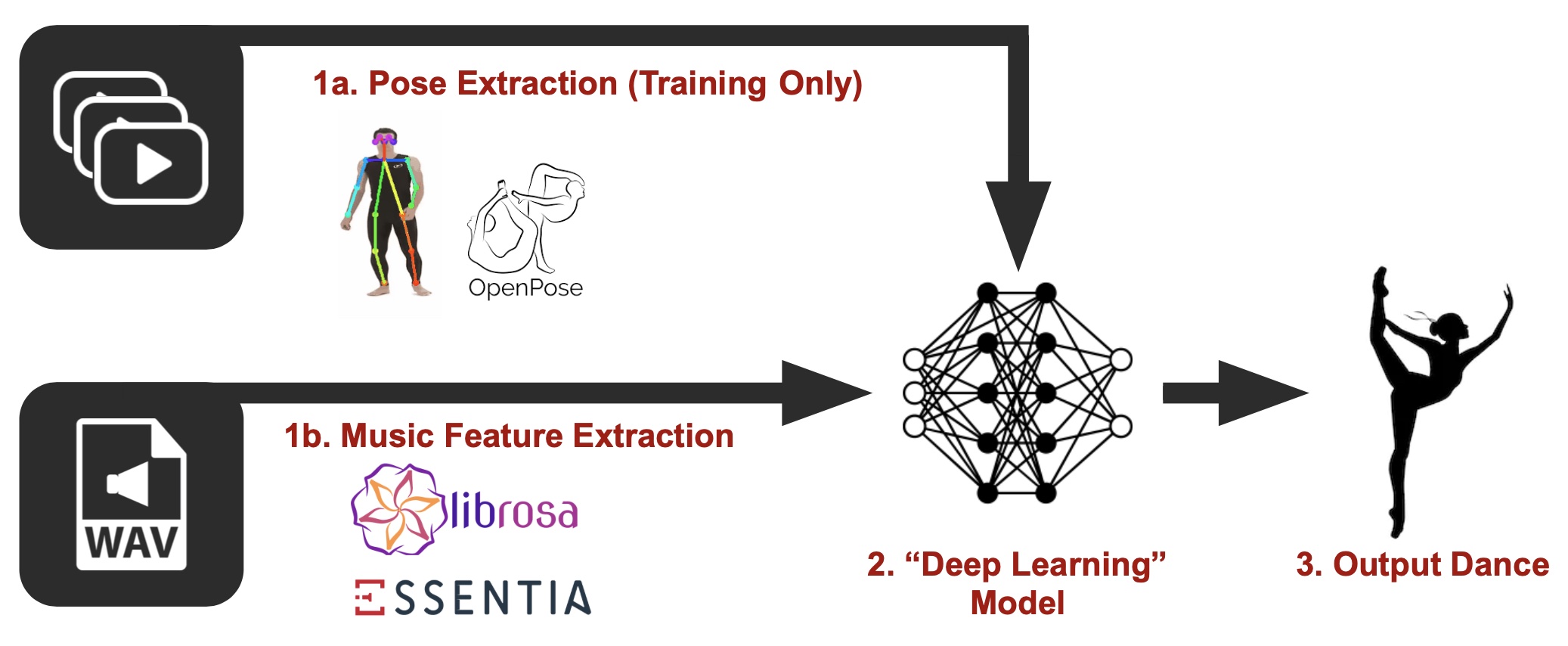
Music to Dance - An Overview
Just like any other machine learning model, an input dataset is required
to be fed into the model. There
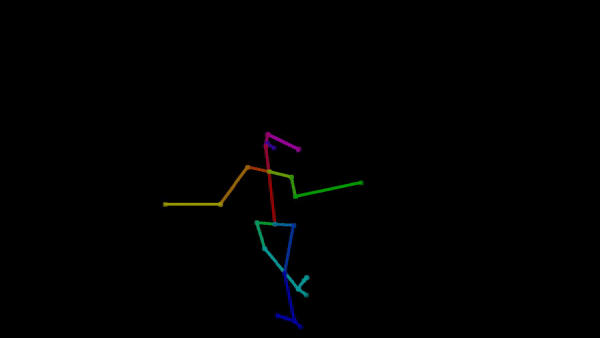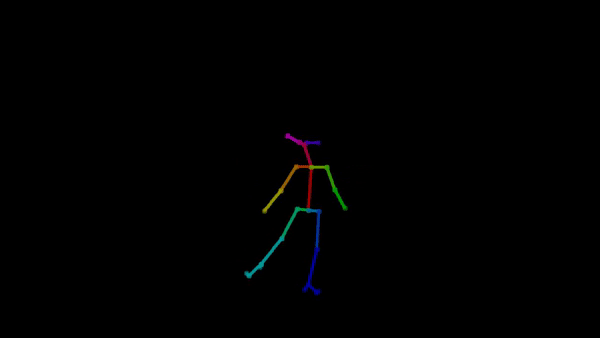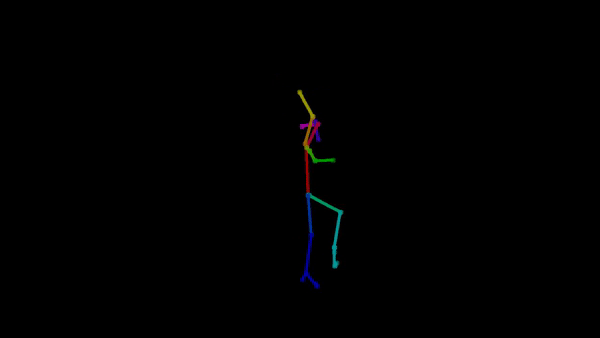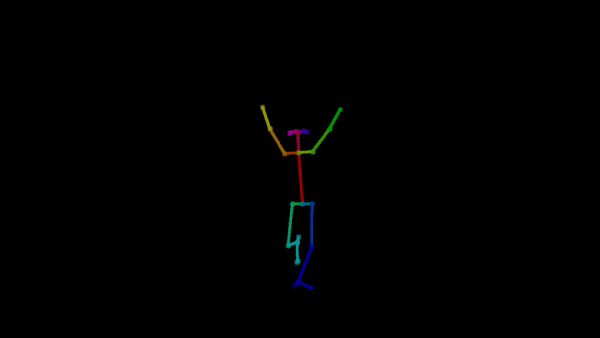
are two parts of the preprocessed dataset here: one is the pose extraction, where tools such as OpenPose
can be used to extract human body movements from video as key joints. As for the audio, there are packages
like librosa and essentia to extract music features, such as the music beats matching and mel frequency
cepstral coefficients, also known as MFCCs. These two parts of the dataset are then sent to a deep
learning model to learn the relationship between the audio and the poses, which can broadly be viewed as
treating the music as features and the poses as labels. Once the model is trained, given a new piece of
music, the model is able to generate a smooth, natural-looking, style-consistent, and beat-matching dance.
Our challenge then becomes creating a model that incorporates this AND allows for interaction with an
artist.
Example of pose extraction
Deep Learning for Generating Dance
Our work builds off a pre-developed machine learning model named DanceRevolution (paper here) as the basis for our system. DanceRevolution uses an
encoder-decoder architecture; at a high level, the encoder learns to 'store' music information in a lower
dimensional space, and the decoder learns a mapping from the encoded coordinates into dance positions.
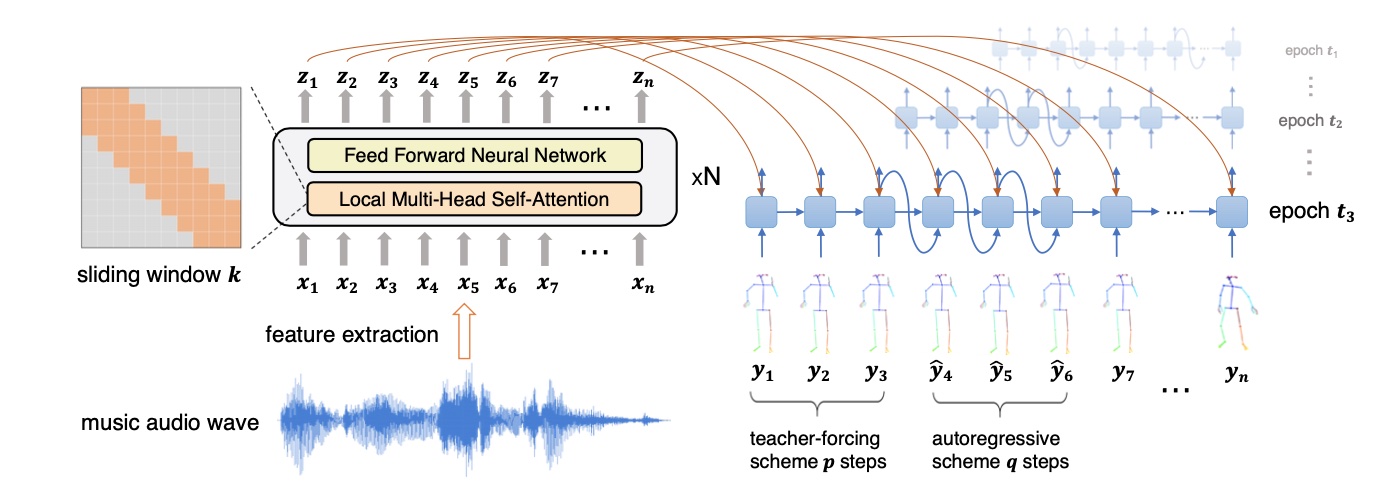
The music is encoded using a transformer with k-nearest neighbors self attention. Self attention means that
at every timestep, the model is able to look at the music features before and after in time to determine the
encoding for the current music timestep. K-nearest neighbors refers to how far into the past or the future
the model can look into. Self attention is great for this type of project because it allows the network to
learn about relationships between music features across time while also considering the effects one time step
has on another (much like in NLP where past and future words can dictate the meaning of the current word).
Decoding
Historically, the issue with autoregressive decoders for generating dance has been the error accumulation
caused by exposure bias. Generative dance models are trained on dance poses from the provided ground-truth
poses, but at inference time, the decoder must predict a new pose based on the previous pose, which was also
predicted. Essentially, the model is not exposed to its own prediction errors during training, so as a result,
the biases of the predicted motion at each time-step during inference time will accumulate through the dance
sequence. Since a 1-minute long dance sequence at 30 FPS is composed of 1800 different poses, the error
accumulation can be quite severe.
What attracted us to Dance Revolution was its curriculum learning strategy to alleviate this exposure bias
problem. During training, this strategy gradually transitions a fully guided teacher-forcing scheme, which
means that the decoder predicts using the ground-truth poses, into an autoregressive scheme, where the decoder
predicts off its own prediction at the previous time-step. The right hand side of this diagram shows that the
input dance sequence that the model is trained on alternates between ground-truth sub-sequences and auto
regressively predicted sub-sequences, which increase in length over the course of training to gradually
minimize exposure bias. This strategy allows for longer length dance generation, compared to older models
whose output would freeze after a few seconds.
Below are the outputs of a model trained on a ballet dataset after differing numbers of epochs when tested on new music. The leftmost video is produced by a model trained over 2,000 epochs, and as evident in the jitteriness and lack of correspondence between the beat and the moves, this model does not have the sufficient capacity to generate realistic dance to the test music. The center video is produced by a model trained over 6,000 epochs. The movements of the key joints are noticeably smoother and more expressive, and the choreography better matches the music. The rightmost video is produced by a model trained over 10,000 epochs. It resembles the under-trained model in its jitteriness, in addition to its repeating of the same spinning move. The regression of the model output after the additional 4,000 epochs likely indicates overfitting, where training has caused the model to fit too closely to the training dataset and limits its capacity to generalize to new music.
User Experience
Our current work has been to create a simple command-line based tool to train and test models. The end goal,
however, has always been to create a web-based interface where people can upload audio clips and have the model
generate dances for them. We plan on soon adding a demo feature to this website to do just that by
incorporating gradio to interface with the ML model seamlessly.
Our Contributions
Our work makes music to dance generation models accessible to a wider audience than ever before by easing
their use and creating templates for some of their possible uses.
In a few words, our work so far has been focused on:
Debugging model preprocessing
Streamlining preprocessing and testing processes
Implementing model fine-tuning to reduce training time
Training a set of pre-trained models to supplement fine-tuning feature and reduce the need to fully
train models
Creating a simple command-line tool to perform all aspects of the dance-generating process (preprocessing,
training, and testing)
Trained models
In works... Come back anytime to check out for new outputs :)
I am a senior electrical engineering student in the computer engineering track at the Cooper Union.
I am deeply interested in machine learning, data science, and software development. As the captain of
Cooper's dance team, the premise of this project immediately peaked my interest, and I cannot wait
for it to be actively used by the team. You can check out more of my work on GitHub and connect with me via
LinkedIn.
Yuval Epstain Ofek
I am a senior electrical engineering student at the Cooper Union concurrently working towards a
master’s degree. I love signal processing, mathematics, & machine learning and take pleasure in
applying theories from these fields to my projects. Check out some of my projects on my Github
here, connect via LinkedIn
here, or send me an email! There is nothing
better than chatting and sharing my work with others :)
Crystal Yuecen Wang
I am a senior electrical Engineering student at the Cooper Union with a computer engineering focus track. I love web development, software engineering, artificial intelligence, & machine learning ! Feel free to checkout some of my projects on my Github. During my spare time, I love music, cooking, netflix, and traveling :)